This note continues to explore the auto-scaling concept I discussed in my note -create an ASG and load balancer with Terraform, so please read that note before this one.
After creating the Amazon EC2 Auto Scaling group, the application development team would require the scaling policies to manage the correct number of Amazon EC2 instances. That way, the Amazon EC2 instances will continue to serve customer requests and use the least number of instances to host the application. Using adequate Amazon EC2 instances leads to cost savings for the project. In the previous note (linked above), I mentioned three use cases where an Amazon EC2 Auto Scaling group can be beneficial. I’ll cover the second use case: Can the number of Amazon EC2 instances be scaled based on a metric like CPU usage?
Before I dive into explaining the code, let me explain the concept. Suppose a load balancer with a round-robin algorithm routes traffic to three Amazon EC2 instances hosting an application. Until a certain level of high CPU usage, the EC2 instances could continue to serve the customer requests depending on the size of the instance. However, beyond a specific high use, the customers will start observing a delay in processing their requests. As a cloud engineer, you may also notice high CPU utilization metrics for the Amazon EC2 instances. In the case of an Amazon EC2 Auto Scaling group, you can track the high CPU usage for a specific duration and create additional EC2 instances if the usage remains high. With the creation of additional EC2 instances, the CPU utilization will be expected to reduce. The Amazon EC2 Auto Scaling group manages that via scaling policies.
Scaling policies could be dynamic, predictive, or scheduled. In the current use case, I am using the dynamic scaling policy. Scaling policies are of two types - increasing and decreasing. Similar to increasing, if the CPU usage drops below a specific percentage, the Amazon EC2 Auto Scaling group would trigger a scale-in activity where the scaling policies would reduce the total number of Amazon EC2 instances. The scale-out and scale-in policy actions are managed via the Amazon CloudWatch alarm. The Amazon CloudWatch alarm tracks the CPU Utilization metric and, when a specific condition is met, triggers the alarm and takes a particular Auto Scaling action.
Let me now explain this with the Terraform code in my GitHub repository: add-asg-elb-terraform/autoscaling.tf
As I stated earlier, there are two scaling activities: increasing and decreasing. Each scaling policy is managed via an Amazon CloudWatch alarm. Hence, there are four additional resources.
1. Create an Amazon EC2 Auto Scaling group policy to scale out
 As you can see from the image above, the auto-scaling policy adds one Amazon EC2 instance to the existing Amazon EC2 Auto Scaling group. The
As you can see from the image above, the auto-scaling policy adds one Amazon EC2 instance to the existing Amazon EC2 Auto Scaling group. The cooldown property is the number of seconds after a scaling activity completes and before the next scaling activity can start, provided the Amazon CloudWatch alarm is still in the “in alarm” state.
2. Create an Amazon CloudWatch metric alarm to track the CPU metric and trigger a scale-out activity
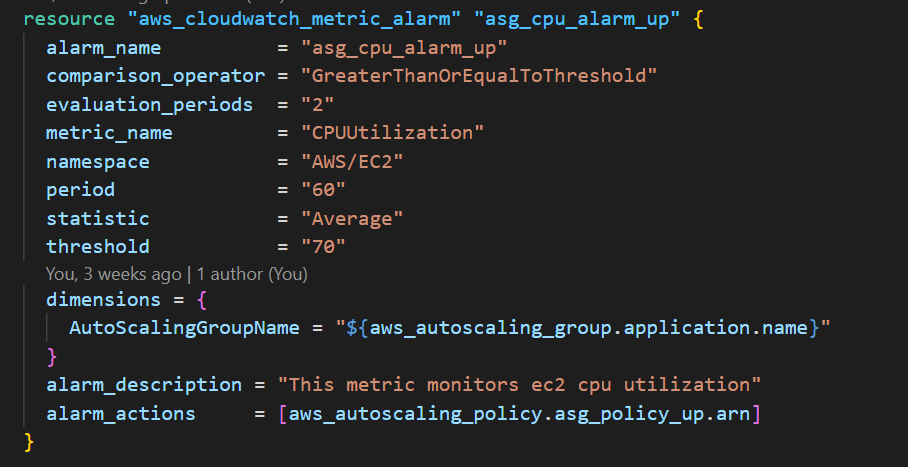 An Amazon CloudWatch alarm triggers the Amazon EC2 Auto Scaling group policy to act provided a specific condition is met. In the code snippet above, if the CPU utilization of an instance in the Amazon EC2 Auto Scaling group crosses the threshold of 70% and remains there for two evaluation periods of 60 seconds each, the alarm state would change to “In alarm,” and the alarm action would take effect. The effect here is to trigger the Amazon EC2 Auto Scaling group’s scaling policy to add an Amazon EC2 instance to the group.
An Amazon CloudWatch alarm triggers the Amazon EC2 Auto Scaling group policy to act provided a specific condition is met. In the code snippet above, if the CPU utilization of an instance in the Amazon EC2 Auto Scaling group crosses the threshold of 70% and remains there for two evaluation periods of 60 seconds each, the alarm state would change to “In alarm,” and the alarm action would take effect. The effect here is to trigger the Amazon EC2 Auto Scaling group’s scaling policy to add an Amazon EC2 instance to the group.
An Amazon EC2 Auto Scaling group with only a scale-out policy is an incomplete strategy without a scale-in policy. Just as a scale-out policy adds Amazon EC2 instances when specific conditions are met, a scale-in policy is needed to remove Amazon EC2 instances when the conditions change. In this case, the below two resources address that aspect.
3. Create an Amazon EC2 Auto Scaling group policy to scale in
 As you can see from the image above, the auto-scaling policy removes an Amazon EC2 instance from the existing Amazon EC2 Auto Scaling group.
As you can see from the image above, the auto-scaling policy removes an Amazon EC2 instance from the existing Amazon EC2 Auto Scaling group.
4. Create an Amazon CloudWatch metric alarm to track the CPU metric and trigger a scale-in activity
 Here, the conditions are on the lower side. So if the CPU utilization drops below the threshold of 30% and remains there for two evaluation periods of 60 seconds each, the alarm action of triggering the Amazon EC2 Auto Scaling group’s scale-in policy would go into effect. The scale-in policy would continue to remove instances until the number of instances in the Amazon EC2 Auto Scaling group equals the desired capacity.
Here, the conditions are on the lower side. So if the CPU utilization drops below the threshold of 30% and remains there for two evaluation periods of 60 seconds each, the alarm action of triggering the Amazon EC2 Auto Scaling group’s scale-in policy would go into effect. The scale-in policy would continue to remove instances until the number of instances in the Amazon EC2 Auto Scaling group equals the desired capacity.
So, that addresses the code aspect. Now, let me demonstrate the steps to test both scaling policies.
Since the Amazon EC2 Auto Scaling group tracks the CPU Utilization metric, I installed a stress utility on the EC2 instance. The user_data script has the code to install that. Then I followed the steps here: generate load to add stress to the Amazon EC2 instances.
TL;DR: Connect to any Amazon EC2 instance using Session Manager and run the command sudo stress --cpu 8 --vm-bytes $(awk '/MemAvailable/{printf "%d\n", $2 * 0.9;}' < /proc/meminfo)k --vm-keep -m 1 . Press Ctrl+C to stop the script after 4 minutes. You’ll see the high percentage if you navigate to the Amazon EC2 instance’s Monitoring Tab and check for CPU utilization. You will also notice that the rising CPU utilization triggered the Amazon CloudWatch monitoring alarm, which triggers the scale-out event.
I found new activities recorded under the Activity History of the Auto Scaling group.
 After approximately 5 minutes or so, another EC2 instance was added by the scaling policy, and I saw six instances. Even if there is high CPU consumption, there won’t be any more Amazon EC2 instances because the maximum size specified in the Amazon EC2 Auto Scaling group is 6.
After approximately 5 minutes or so, another EC2 instance was added by the scaling policy, and I saw six instances. Even if there is high CPU consumption, there won’t be any more Amazon EC2 instances because the maximum size specified in the Amazon EC2 Auto Scaling group is 6.
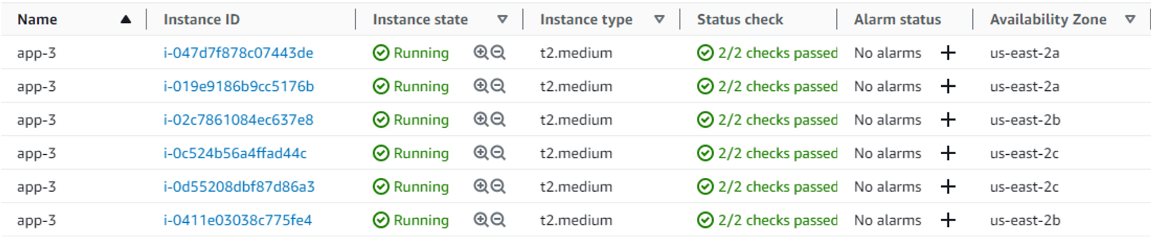 After completing health check evaluations, the load balancer was routing traffic to all the Amazon EC2 instances. Here is the image of the load balancer’s target group.
After completing health check evaluations, the load balancer was routing traffic to all the Amazon EC2 instances. Here is the image of the load balancer’s target group.
 Note: If you look carefully at the Instance IDs under activity history, instance IDs won’t match because after launching, the health check kept failing for one of them, and they had to be re-provisioned.
Note: If you look carefully at the Instance IDs under activity history, instance IDs won’t match because after launching, the health check kept failing for one of them, and they had to be re-provisioned.
And that is how the scale-out policy works. Once I stopped the stress script [Ctrl+C], the CPU utilization was reduced to below 30%. Due to this, the Amazon CloudWatch alarm went into effect and triggered the Amazon EC2 Auto Scaling group’s scale-in policy. Gradually, the Amazon EC2 instances were removed one by one until the number of active instances equaled the desired capacity.
If I had not added the scale-in policy, the number of Amazon EC2 instances would have remained high, defeating the purpose of having an auto-scaling group.
I hope you understand how the Amazon EC2 Auto Scaling group’s scaling policies work. Let me know if you have any questions.